
この文章はMySQLにあるさまざまなコマンドを簡単に説明したものです.ここに書いてあるコマンドをすべて理解すれば,テーブルの操作を最低限行うことができます.ぜひ習得しましょう.
-
MySQL Commnand Line Clientの起動
MySQLの命令(クエリという)をコマンドプロンプト上で実行(発行ともいう)するには,”MySQL 5.7 Command Line Client”を使います.ここでは,このアプリケーションを利用して,MySQLのクエリを発行します.MySQL 5.7 Command Line Clientには,通常版とunicode版が存在します.Windows10の場合には,下図のようにすべてのアプリ→MySQLの下に,2つのMySQL Command Line Clientがあるように見えます.これらにしばらくマウスカーソルを合わせるとTipsが現れますので,それで区別してください.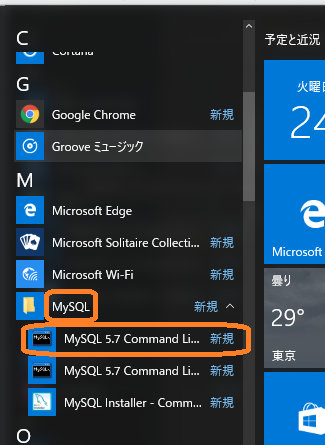
Windows8の場合にも同様で,下図のように見た目が同じアイコンが並んでいますが,マウスカーソルを合わせるとTipsが現れるので,それによって区別し,通常版を実行してください.Windows7の場合には,”スタート” → ”すべてのプログラム” → ”MySQL” → ”MySQL Server5.7” → ”MySQL 5.7 Command Line Client” を実行してください.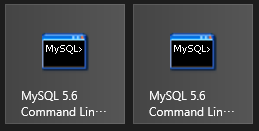
実行すると, 下図のようなウィンドウが開かれます.ここでは,インストール後に行ったコンフィギュレーションにて設定したルートのパスワードを 入力します.そして,パスワードを正しく入力しエンターキーを押すと,下図のような表示がなされます.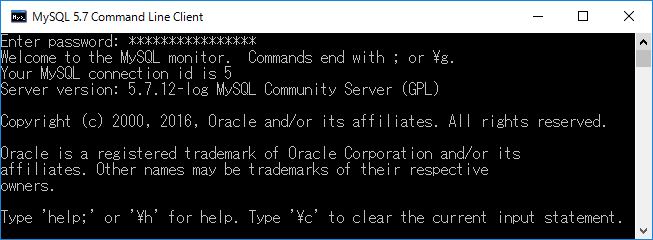
ためしに,こ のMySQLのバージョンを表示してみます.”select version();”+エンターキーを押すと,下図のようにバージョンが表示されます.
先ほどの”select version();”をよく 見ると右端に”;”があるでしょう. これはSQLのクエリの末端を表す記号です.この記号が入力されるまで,MySQLのインタプリタは,クエリが終了していないとみなします.そのため,下図のよ うに複数行にわたり命令を記述することも可能となっています.また,MySQLは行ごとにコマンドを記憶しています.キーボードの”↑”キーを押すたびに,前に入力したコマンド がさかのぼって表示されます.この機能により,何度か同じコマンドを実行するときに効率よく作業が行うことができますので,是非身に着けておいてください.
”?”+ エンターキーを押すと,下図のように MySQLのコマンドのヘルプが閲覧できます.コマンド名がわからなくなったときに閲覧してください.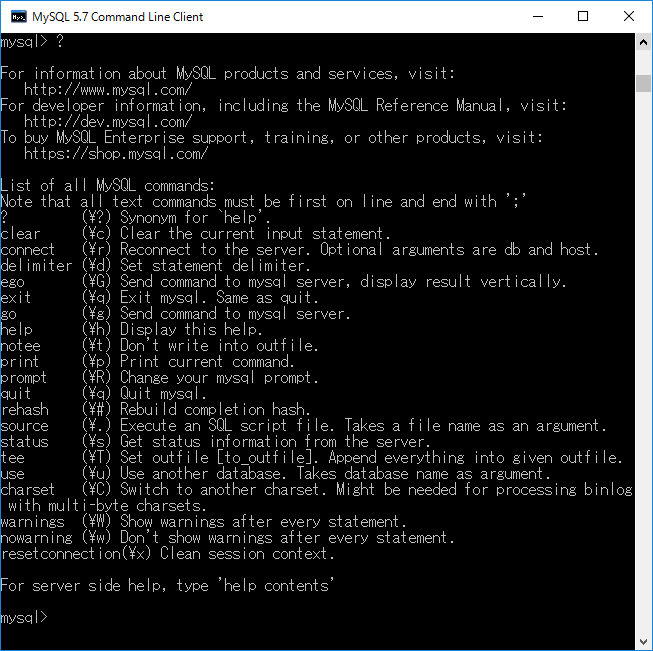
-
主なコマンドの説明
以下には,主なコマンドを実際に実行します.なお,下記の書式は非常に簡略化しています.正確な書式を調べるときにはここにあるオンラインリファレンスを参照してください.-
show命令
show {databases | tables [from データベース名] | fields from テーブル名 }
show databases;+エンター キーを押すと下図のように現在登録されているデータベースを表示します.
インストールした時点で,下記の表に示すデータベースが登録されています.
information_schema MySQLの環境等に 関する情報が格納されている. mysql MySQL の管理用データベース. performance _schema MySQLの稼働状況を蓄積しているデータベース. sys performance schema をわかりやすく表示するためのデータベース.
なお,show tables; は,テーブルの内容を表示することができます.実際に使用している様子は後述するので参照してください.また,show fields from テーブル名;についても後述しているので参照してください.
続いてconnect命令を説明したいのですが,その前にテスト用データベースを作成します.データベースの作成方法はこちらで説明していますが,ここでは先取りしてテスト用データベースを作成してしまいます.create database test;+エンターキーを入力してください.
-
connect命令
connect データベース名;
テスト用デー タをtestデータベースに作成します.connect test;+エンターキーを押してください.次にtest に定義されているテーブルを確認するために show tables;+ エンターキーと入力します.その結果,下図のように,現在はテーブルがまったくないので”Empty set”と表示されます.なお,このとき"Connection id"という項目が上から2行目にありますが,この値は接続するたびに変わりますので,皆さんが実行したときには違うかもしれませんが気にしないでください.

-
create命令
-
テーブルの作成
create table テーブル名 (フィールド名 型 [unique] [not null] [primary key], ...);
ここでは例として,講義に関するテーブルを作成し,”subject”という名前とし,このテーブルに下記の表のような項目を作成します.
項目 フィールド データの型 NULLを許すか 主キーか 通し番号 id 整数10桁 × ○ 講義名 s_name 半角50文字 × × 担当教員 t_name 半角10文字 × × これらの項目をMySQLで作成するとき,create table subject (id int(10) unique not null, s_name char(50) not null, t_name char(10) not null);+エンターキーのように入力します.ここで,主キーである”id”を”primary key”と指定することもでき,”primary key”と指定された場合には,自動的に”not null”となります.

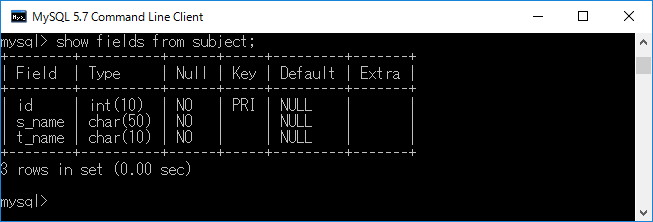
作成したテーブルの項目をshowコマンド で閲覧します.具体的にはshow fields from subject;+エンターキーのように入力します.その結果,下記のように項目の名前やデータの型などを見ることができます.なお,”Null”は項目がない状態であるNull値の入力を許可するかを表しており,”Key”は”PRI”となっており,主キーであるかを示しています.
テーブルによっては,2つのフィールドで1つの主キーとする場合があります.この場合には以下のような書式で主キーを指定することができます.
create table テーブル名 (フィールド名1 型1, フィールド名2 型2, ..., primary key(フィールド名1, フィールド名2) );
例えば,科目ID(subject_id)と学籍番号(student_id)がprimary key,成績(score)が従属するフィールドだとします.この場合,テーブルはcreate table seiseki(subject_id int, student_id int, score int, primary key(subject_id, student_id) );+エンターキーとなります.そして,show fields from seiseki;+エンターキーと入力すると下図のようになります.subject_idとstudent_idがPRIになっていることを確認してください.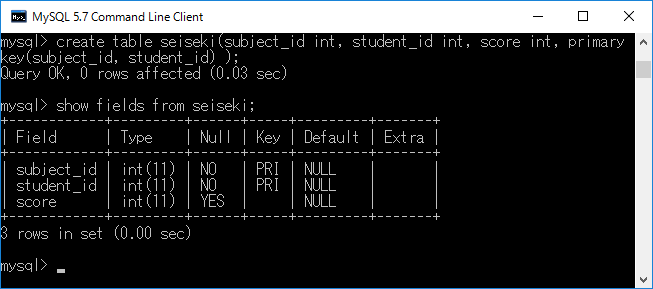
フィールドの属性には,上記で説明したもの以外にもindexやforeign keyなどがあります.詳しくは「フィールド属性について」を参照してください.
-
データベースの作成
create database データベース名; 新しいデータベースを作成するときもcreate命令を用います. ただし,今回はcreateの後ろにdatabaseを付け,さらにデータベース名を書きます.
以下に,test10というデータベースを作成した例を示します.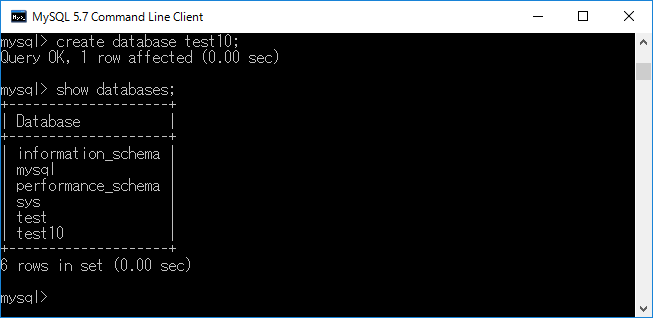
-
-
insert命令
insert into テーブル名 values(値 ,...); -
一行追加(すべての項目)
作成した項目にデータを挿入するには,insert命令を使用します.ここで挿入するデータを下記の表にまとめます.
通し番号 担当教科 教員名 1 UNIXネットワークプログラミング 大矢 2 モンテカルロ計算入門 伊藤 3 データベースとSQL 芦田
これらのデータを入力するとき,以下のようなコマンドを実行します.
insert into subject values(1, 'UNIXネットワークプログラミング','大矢');+エンターキー
insert into subject values(2, 'モンテカルロ計算法','伊藤');+エンターキー
insert into subject values(3, 'データベースとSQL', '芦田');+エンターキー
実行結果を下に示します.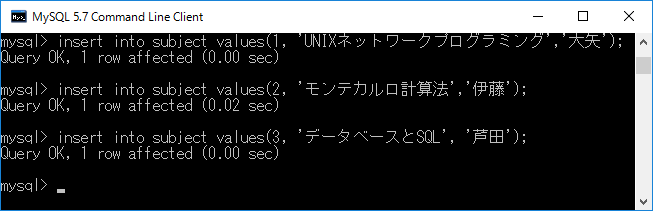
ここで注意することは,必ず挿入する行の列数とデータ数が一致しなければならないことと,入力データが数字以外の場合は,ダブルクォーテーション(")もしくはシングルクォーテーション(')でくくることです.
-
一行追加(一部の項目)
項目名を指定して一部の項目のみを挿入するには,into とvalues の間にテーブル名(列名,・・)を指定します.values の後は,先ほどの例と同じです.具体的には,insert into subject(id, s_name) values (4,'実務訓練の発表会');+エンターキーと入力します.ただし今回設計したテーブルについては,”t_name”がnullであることを許可しないため,この挿入は下図のように失敗します.

-
-
select命令
select フィールド from テーブル名 [where 条件];
”select” 命令はテーブルの表示や,条件 付きテーブル表示(検索)ができます.ここでは5つほど実例を挙げて説明します.-
すべてを表示
まずテーブ ルの内容をすべて表示させます.それにはselect * from subject;+ エンターキーと入力します.ここで”*”は,すべての列名を表します.なお”*”は省略も可能です.実行結果を下に示します.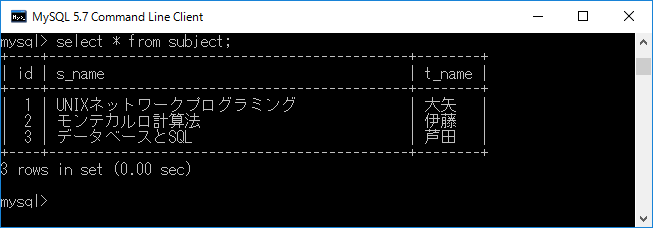
-
一部のフィールドについて表示
次にテー ブル名 subject の列名 id と t_name を表示させます.具体的には,select id, t_name from subject;+エンターキーと入力します.このように,”select” と ”from”の間に列名をコンマ(,)区切りで記述することで指定された情報を表示できます.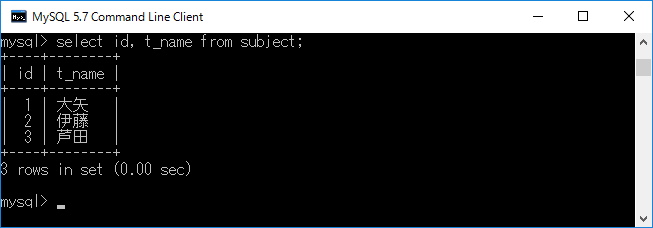
-
条件のもとに表示
次にテーブル名” subject”から列名”id”のデータが”3”であるものを表示させます.それには,select * from subject where id = 3;+エンターキーと入力します.なお,ここでは”id = 3”としたが,このほかの関係演算子として,”!=”,”<,”>”,”<=”,”>=”なども使えます.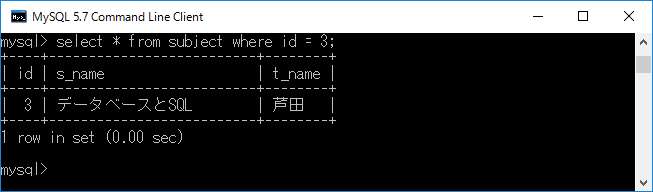
-
文字列の検索結果に合致したデータを表示
テーブル名 subject の列名 s_name のデータ内の文字列に ”ー”(長音を示す記号.のばし棒)が含まれるものを検索し表示します.それには,select * from subject where s_name like "%ー%";+ エンターキーと入力します.ここでパーセント記号は,正規表現でいうところの”*”と 同じです.つまり検索したい文字列の前後にパーセント(%)をつけると検索対象のどこでも構わないこと意味し,文字列の先頭につけるとその文字列で終わるもの,逆に一番最後につけると,その文字列で始まるのもを検索します.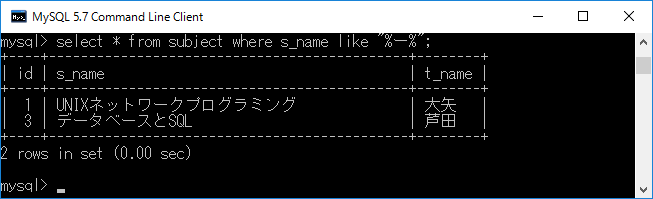
-
複数の条件に合致したデータを表示
先ほどの条件に加えて,t_nameのデータ内の文字列に”芦田”が含まれているものを検索し表示します.それには,select * from subject where s_name like "%ー%" and t_name like "%芦田%";+エンターキーと入力します.このよう に,where句の条件部分に andやor を使って複数の条件を記述できます.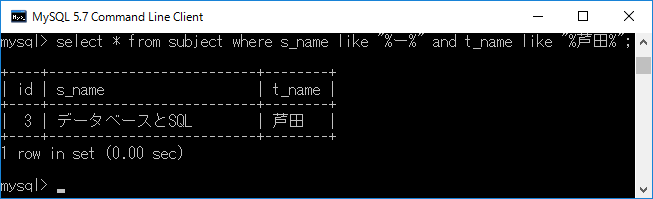
-
-
delete命令
delete 命令は,テーブルから行を削除する命令です.delete from テーブル名 [where 条件]; -
無条件にテーブルの データを削除
テーブルの中にあるデー タをすべて削除する場合,delete from テーブル名;+エンターキーと入力します.下図にその様子を示します.このように,データをすべて消してしまうので,使用するときには十分な注意が必要です.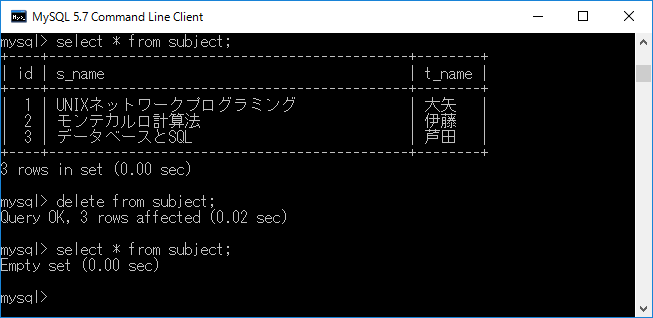
なお,下記のコマンドを実行したのち,もう一度3レコードをinsert命令で追加しておいてください.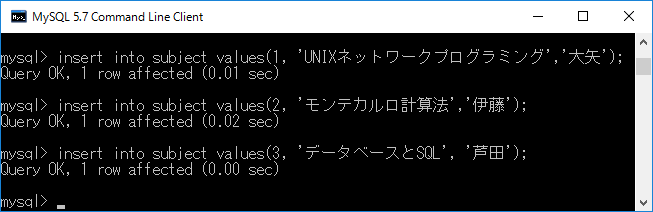
-
条件をつけて一部のデータを削除
where 句にある条件に該当する行が削除されます.例として,idが3である行を削除する場合,delete from subject where id=3;+ エンターキーと入力します(下図をご覧ください).なお,条件に該当する行がなくても命令は実行され,エラーにはなりませんが,当然結果は変わりません.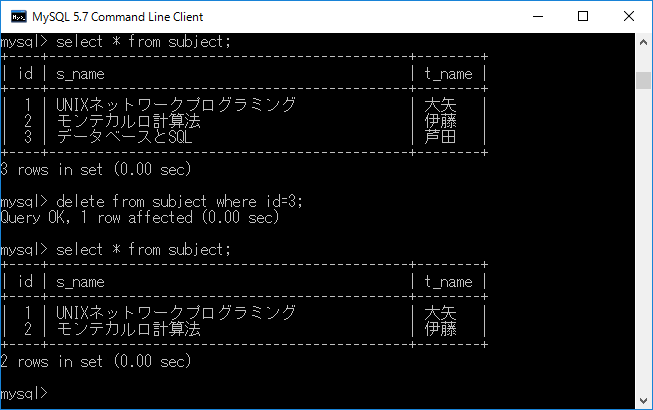
なお,ここでも消してしまったレコードを復活すべく,下記のようにしてください.
-
-
update 命令
update 命令は,テーブルのデータを更新する命令です.update テーブル名 set フィールド名 = データ ,... [where 条件]; -
条件をつけて一部のデータのみを更新
例 として,”t_name” が”芦田”である行の,”s_name”(現在,”データベースとSQL”)を”Verilog HDLによるLSI設計”に更新します.その場合,update subject set s_name='Verilog HDLによるLSI設計' where t_name='芦田';+ エンターキーと入力する.その様子を下図に示します.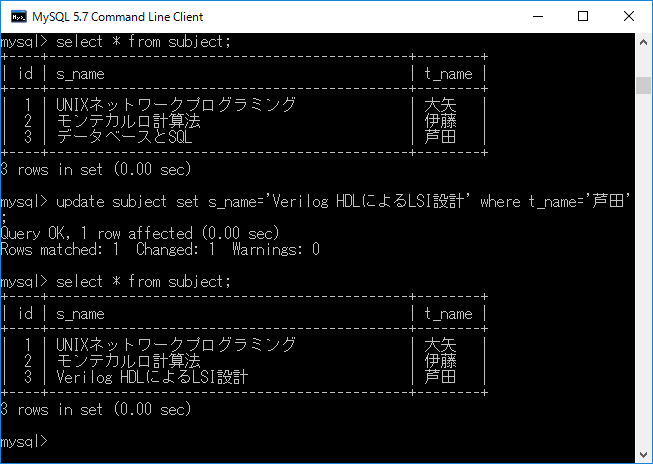
-
指定したフィールド名のデータをすべて更新
例として”t_name” (現在,”大矢”,”伊藤”,”芦田”の3種類があるとします)をすべて”芦田”に更新します.その場合,update subject set t_name='芦田';+ エンターキーと入力します.その様子を下図に示します.このように,すべての行の t_name の列が変更されてしまうので使用時には注意が必要です.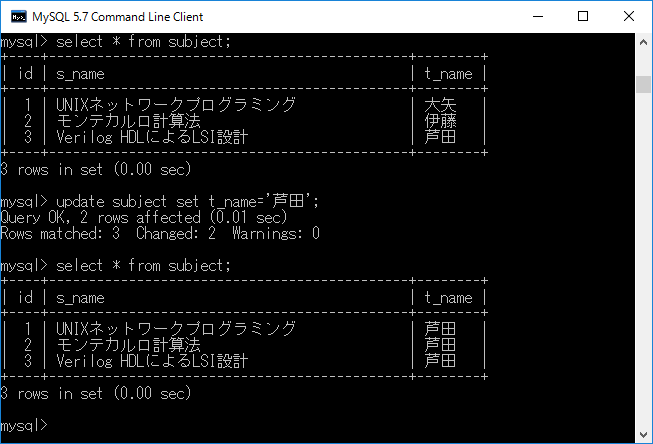
-
-
join 命令
-
内部結合
内部結合とは複数のテーブル間で同一の条件を満たすレコードのみを抽出して表示する方法です.この内部結合を使用するには,select命令にinner join命令とonを付加して条件指定する方法と,onの代わりにusingを付加して結合列を指定する方法があります.この例を示すために,まず”seiseki”というテーブルを作成します.
create table seiseki (id int(10) unique not null, score int(10) not null);+ エンターキー
insert into seiseki values(01, 80);+ エンターキー
insert into seiseki values(02, 100);+ エンターキー
insert into seiseki values(03, 90);+ エンターキー
作成した結果を下図に示します.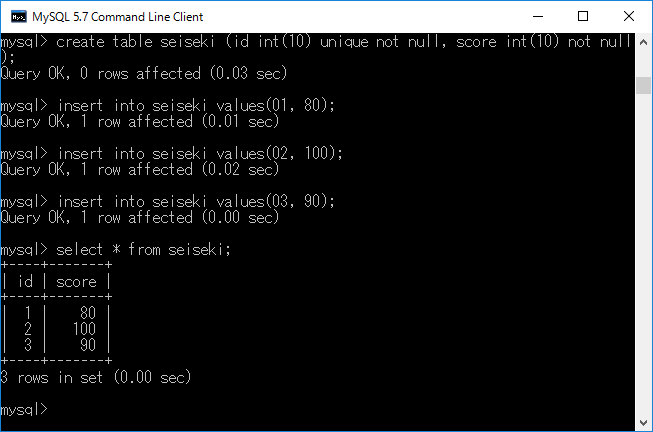
-
onを用いた内部結合
select * from テーブル1 inner join テーブル2 on 結合条件;
例としてid 列を結合条件として,subjectテーブルにseisekiテーブルを内部結合します.それには,select * from subject inner join seiseki on subject.id=seiseki.id;+ エンターキーと入力します.ここで,”.”はテーブルとフィールドをつなぐ記号であり,たとえば”subject.id”とは,テーブル”subject” の中のフィールド”id”を示しています.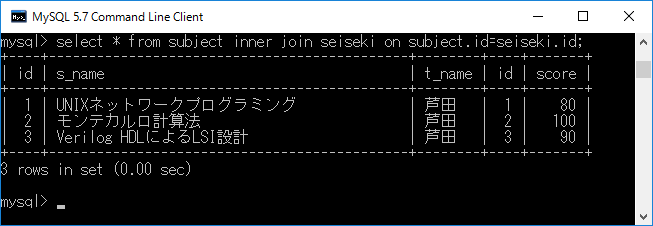
結合条件に使用した列を表示しないようにして見やすくするには,select s_name, t_name, seiseki.score from subject inner join seiseki on subject.id=seiseki.id;+ エンターキーと入力します.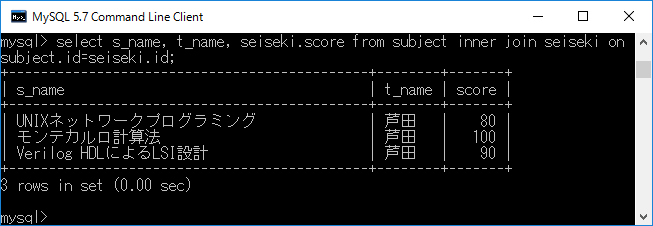
-
using を用いた内部結合
例 としてid 列を結合条件として,subjectテーブルにseisekiテーブルを内部結合します.それには,select * from subject inner join seiseki using (id);+ エンターキーと入力します.ここでは,subjectおよびseiskiテーブル両方に”id”フィールドが含まれており,同じ”id”を持つ行を1つにま とめています.その様子を下図に示します.select * from テーブル1 inner join テーブル2 using ( 列名 ); 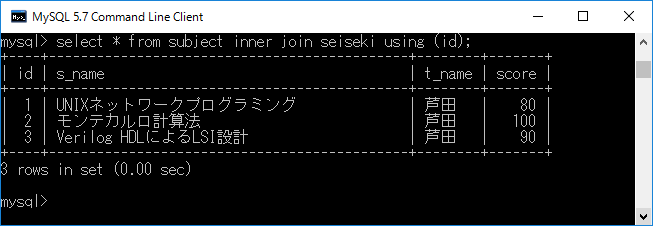
先ほどのon を用いた内部結合と同様 に,結合条件に使用した列を表示しないようにして見やすくするには,select s_name, t_name, seiseki.score from subject inner join seiseki using(id);+ エンターキーと入力します.その様子を下図に示します.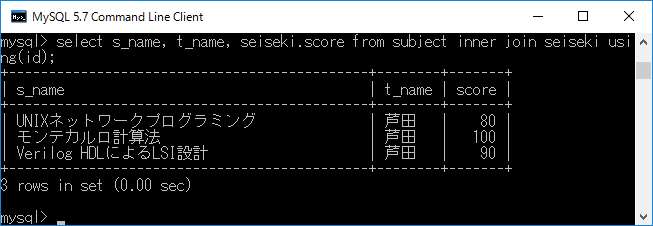
-
where を用いた内部結合
select * from テーブル1, テーブル2, テーブル3,... where 条件;
from以下にテーブルを列挙し,whereに条件を書くことで, 前 例と同じ結果が得られます.それにはselect * from subject, seiseki where seiseki.id=subject.id;+ エンターキーと入力します.その様子を下図に示します.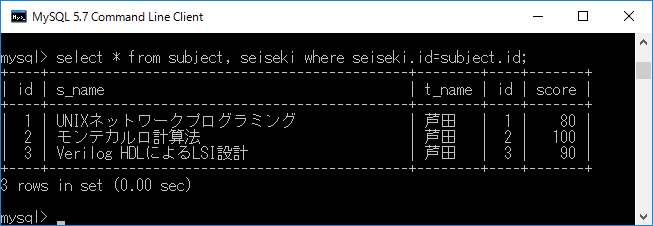
この方法を用いると,テーブルを3つ以上連 結することもできます.なお,inner joinを用いた場合でも同様にテーブルを3つ以上連結できますが,ここではその書き方を省略します.
-
-
外部結合
内部結合では,フィールド同士 の値が一致する場合,結合を行いました.外部結合では,フィールド同士の値が一致した場合だけでなく,一致しなかったレコードについても抽出し結合を行います.具体的な例を示すために2つのテーブルを作成します.
create table test1( key1 char(8), data1 int, data2 int, data3 int);+ エンターキー
create table test2( key1 char(8), code1 char(8));+ エンターキー
insert into test1 values('a001', 1, 2, 3);+ エンターキー
insert into test1 values('a011', 1, 2, 3);+ エンターキー
insert into test1 values('b002', 10, 20, 30);+ エンターキー
insert into test1 values('c003', 100, 200, 300);+ エンターキー
insert into test2 values('abc01', 'a001');+ エンターキー
insert into test2 values('abc02', 'a011');+ エンターキー
insert into test2 values('abc03', 'z999');+ エンターキー
作成した結果,下図のようなテーブルが2つ作成されます.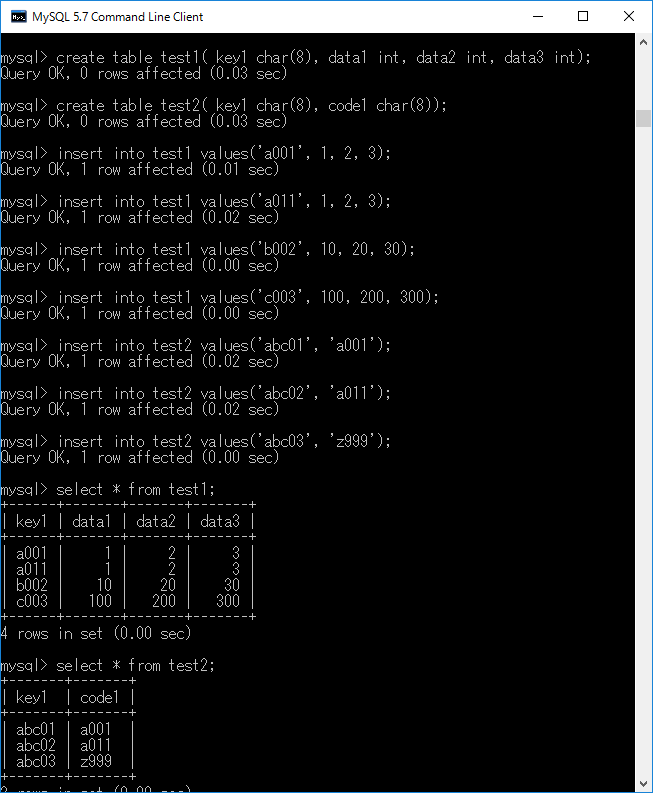
-
左結合(left join)
select * from テーブル1 left join テーブル2 on 条件
まず具体例を示してから説明します.select test2.key1, code1, data1, data2, data3 from test2 left join test1 on test2.code1 = test1.key1;+ エンターキーと入力すると,下図のようなテーブルが得られます.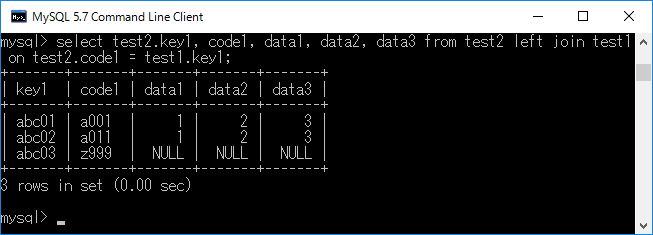
ここで,test2.code1を列挙すると{'a001', 'a011', 'z999'}であり,test1.key1を列挙すると{'a001', 'a011', 'b002', 'c003'}です.inner joinであれば,{'a001', 'a011'}が該当します.left joinの場合,test1.key1に該当するデータがあればそれと連結し,さらに無いデータ(ここでは'z999')については'NULL'という形でdata1からdata3をセットに含めます. -
右結合(right join)
select * from テーブル1 right join テーブル2 on 条件
その名の通り,左結合の反対の動作をします.具体例を示します.select test2.key1, code1, data1, data2, data3 from test2 right join test1 on test2.code1 = test1.key1;+ エンターキーと入力すると,下図のようなテーブルが得られます.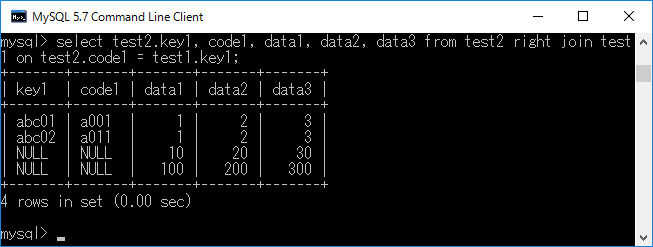
左連結とは違い,test2.code1に該当するデータが無い場合(ここでは'b002'と'c003')について'NULL'という形 でtest2.key1およびtest2.code1をセットに含めます.さらに詳しい連結の方法を知りたい場合にはこちらのサイトがおすすめです.
-
-
all 命令
上記書式は,テーブル1.フィールドとテーブル2.フィールドで,どれにも 該当しないレコードを表示するためのものです.具体例を次に示します.select * from test1 where test1.key1 != all(select code1 from test2);+ エンターキーと入力すると,下図のような結果が得られます.select * from テーブル1 where テーブル1.フィールド != all( select テーブル2.フィールド from テーブル2 ); 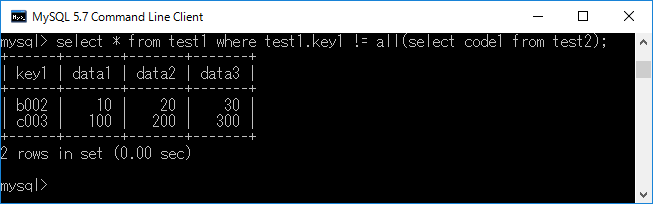
select code1 from test2の結果を列挙すると,{'a001', 'a011', 'z999'}で あり,test1.key1を列挙すると,{'a001', 'a011', 'b002', 'c003'}です.このうち,'a001'と'a011'は共通しているため,それ以外の'b002', 'c003'が表示されます. つまりtest2.code1の全てについて合致しないレコードを抽出したことになり,結果的にtest1.key1からtest2.codelを除いたようになります.
-
alter命令
alter命令は,テーブルのフィールド(カラム)を消去・変更・追加などを行う命令です.ここではカラムの消去と追加の方法についてのみ説明します.-
カラムの消去
alter table テーブル名 drop カラム;
具体例を挙げるためにテーブルを作成します.create table test3 (data1 int, data2 int);+ エンターキーと入力すると,下図のようなテーブルが作成されます.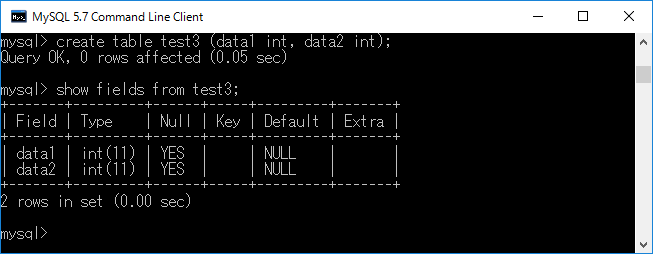
この中で,フィールド'data2'について削除する.それにはalter table test3 drop data2;+ エンターキーと入力します.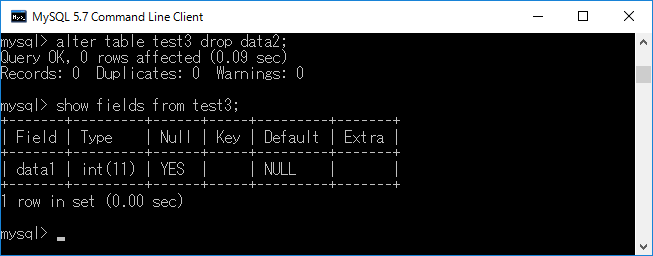
-
カラムの追加
alter table テーブル add 新カラム 新カラムのデータ型など {first | after 既存のカラム};
先ほど作成したテーブルtest3に,カラムdata3(int型 not null)を既存のカラムであるdata1の後ろに作成します.それにはalter table test3 add data3 int not null after data1;+エンターキーと入力します.結果を下図に示します.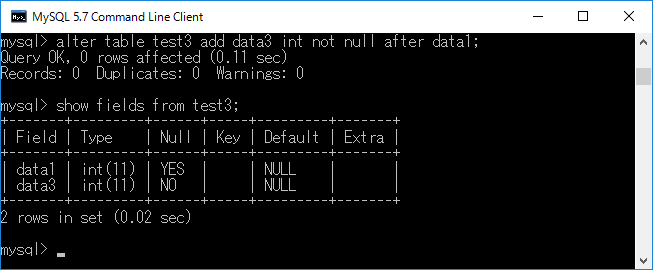
-
テーブルの名前変更
alter table テーブル rename 新テーブル名
先ほど作成したテーブルtest3をtest4に変更します.それにはalter table test3 rename test4;+エンターキーと入力します.結果を下図に示します.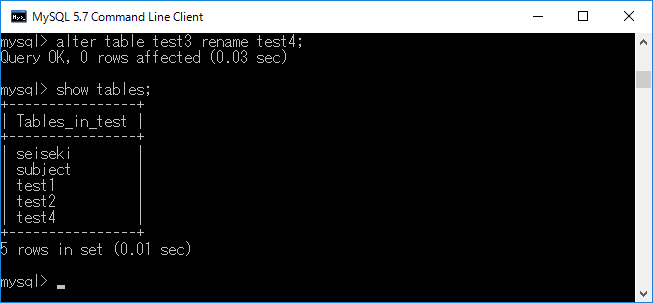
-
-
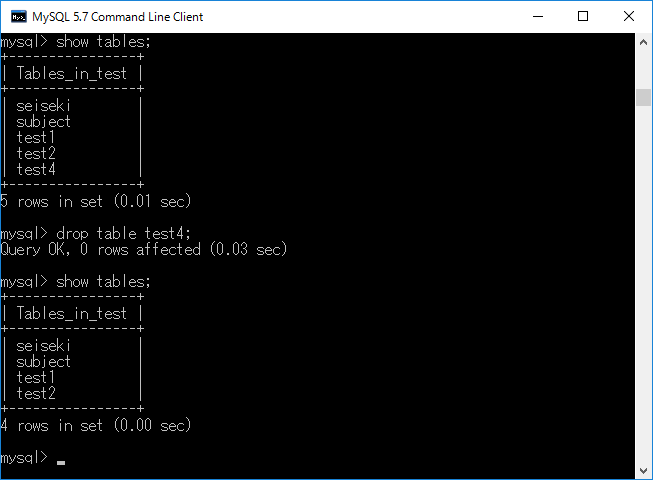
テーブルを削除する場合に用いる命令です.例としてtest4テーブルを削除します.それにはdrop table test4;+ エンターキーと入力します.結果を下図に示す.
-
-
- データのファイル出力
select {出力するテーブル名や条件} into outfile 'ファイルのパス';
例として,先ほど説明したusingを用いた内部結合について,”C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\"フォルダに"test.txt”ファイルに出力します.なお,このフォルダに対してのみ出力できるように現在の設定ではなっています.もし,この制限をなくしたい場合にはこちらを参考にしてください.さて,出力するには,select s_name, t_name, seiseki.score from subject inner join seiseki using(id) into outfile 'C:\\ProgramData\\MySQL\\MySQL Server 5.7\\Uploads\\test.txt';+ エンターキーと入力します.ここで,”test.txt”の前などに”\\”となっているが,これは”\”が特別な文字(エスケープ文字を扱うための記号)であるため,”\”を2つ入力することにより,”\”を表すからです.下に実行結果を示します.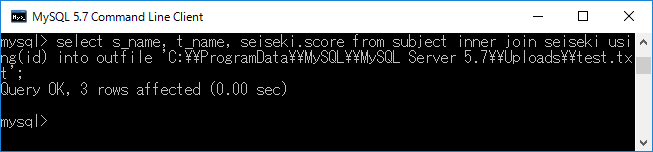
- データファイルからの読み込み
load data infile 'ファイルのパス' into table テーブル名;
先ほど作成した”test.txt”ファイルを,”ichiran”という テーブルに読み込む.それにはまず,テーブル”ichiran”を作成し,その上で読み込みます.作成するにはcreate table ichiran (s_name char(50) not null, t_name char(10) not null, score int(10) not null);+ エンターキーを入力します.その後,load data infile 'C:\\ProgramData\\MySQL\\MySQL Server 5.7\\Uploads\\test.txt' into table ichiran;+ エンターキーを入力します.実行結果と,読み込んだテーブルを下図に示します.
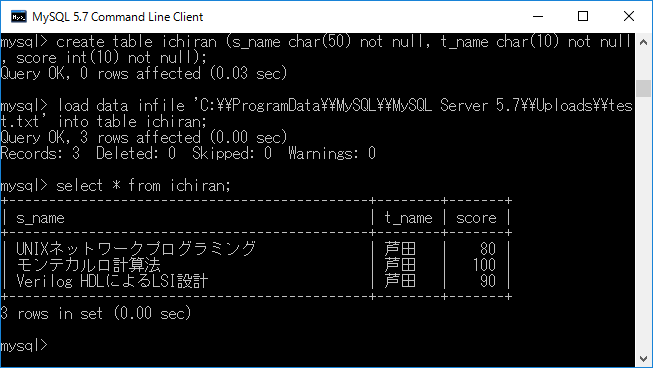
この機能を用いると,Microsoft社製Excelで作成したファイル をMySQLに間接的ではあるが読み込むことができます.詳しくは「MS Excelで作成したテーブルをMySQLに取り込む方法」を参照してください.
- データのファイル出力
- ファイルによるスクリプト処理
たくさんのクエリをまとめて行いたいとき,それらをスクリプトとしてファイルに書いておいて一度に発行するには下に示すsourceコマンドを用います.
たとえば,Cドライブ直下にあるTempフォルダにTest.sqlファイルがあり,このTest.sqlファイルにクエリ群が書かれているとします.この場合,source c:\Temp\test.sql + エンターキーを押します.ここで注意しなければならないことは,これまでのコマンドでは,末尾にセミコロン(;)を付けていましたが,sourceの最後にはセミコロンを付けてはいけません.ただし,ファイルの中にあるSQL文にはセミコロンを付けてください.もし付いていると正しく動作しません.なお,Test.sqlファイルにクエリ群を書くには,メモ帳などのテキストエディタを使用します.source ファイルのパス - MySQL Command Line Clientの終了
quitま たは\qで 終了します.