
DigitRecognitionでは,0~9までの数字しか認識できないようになっています.これを拡張してアルファベットについても認識できるようにしてみましょう.この文書では,「A」というアルファベットを認識できるようにDigitRecognitionを拡張する方法について説明します.
1:辞書の追加
「A」というパターンを新たに追加するため,ここではフリーソフトのgimpを使用してパターンを作成することにします.gimpを立ち上げましたら下図のように新しい画像を作成しましょう.
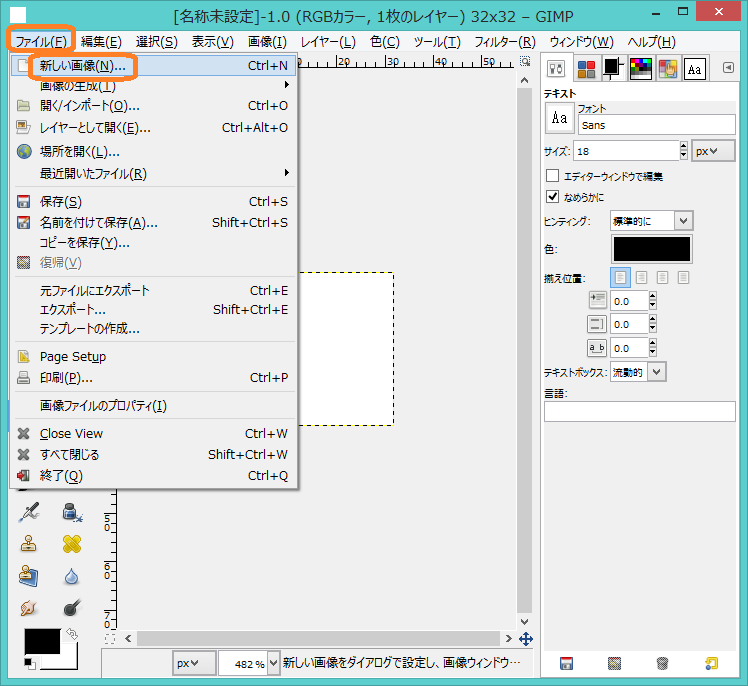
新しい画像のサイズを32×32とします.これは,DigitRecognitionでは32×32の画像サイズを正規化サイズとしているためです.
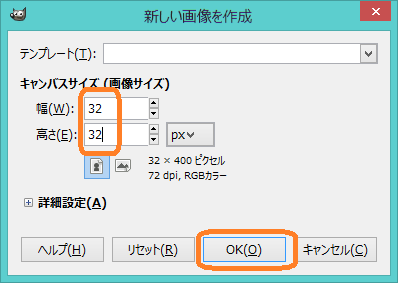
次にAというパターンを追加します.下図のようにテキストを入力するアイコンを選択し,描画したい箇所を適当にクリックします.
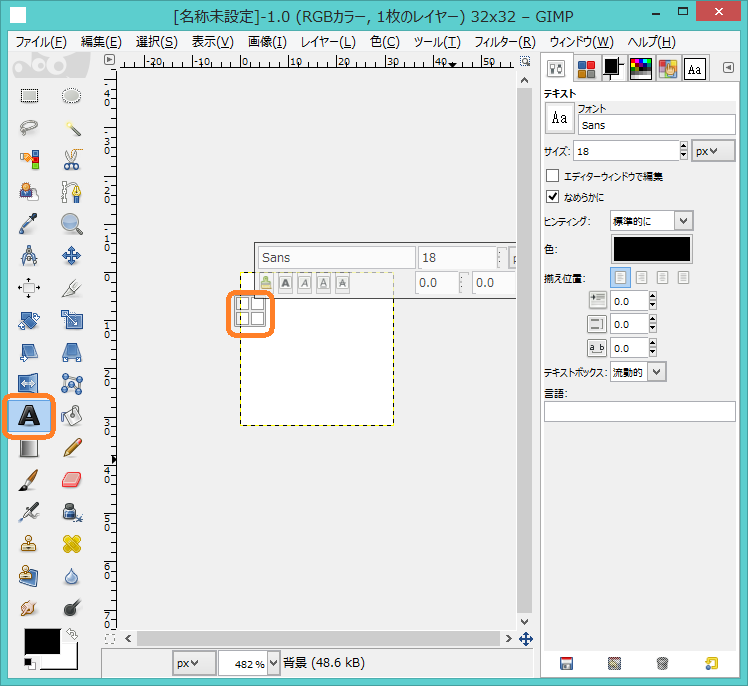
Aという文字を入力したのち,大きさを調整します.Sansというフォントの場合,高さおよそ32とするには41ポイントにすればよいです.他のフォントの場合にはポイントを調整してください.なお,Aのパターンが書かれている四隅にある長方形をドラッグすると,パターンを移動することができます.大きさを調整するときに使ってください.
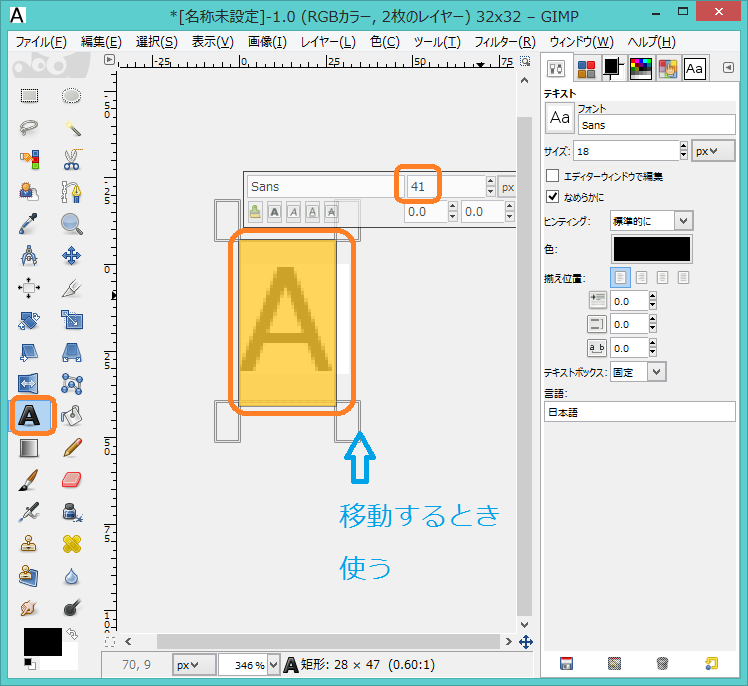
作成しましたパターンは256段階のグレースケールとなっているため,これを2値化します.下のように[画像]⇒[モード]⇒[インデックス]へお進みください.
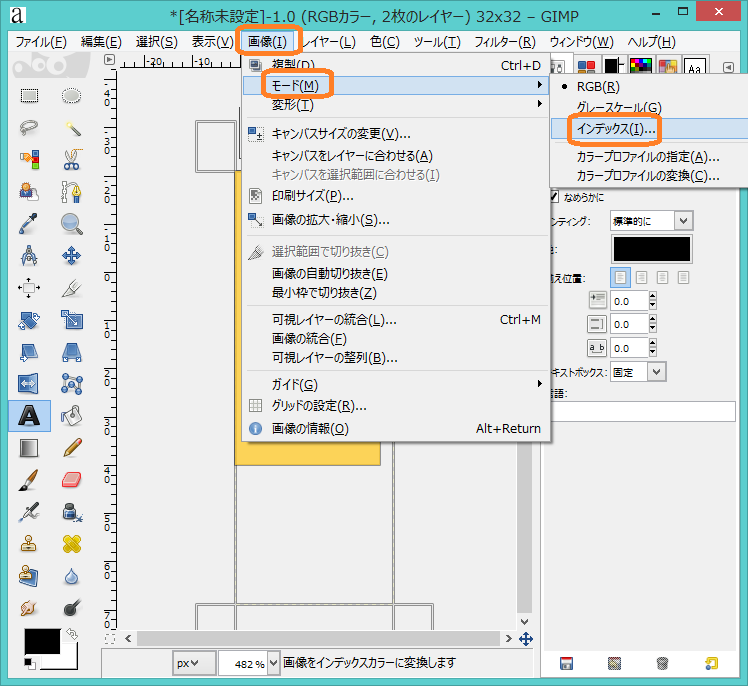
下のように,「モノクロ2階調(1-bit)パレットを使用」を選択してください.
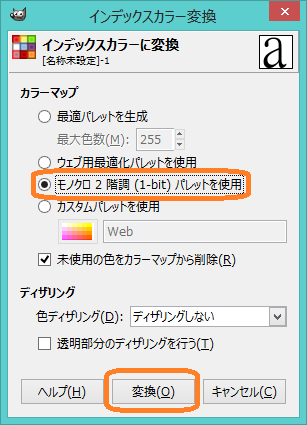
次にパターンのサイズをおおよそ32×32にすべく,拡大を行います.アイコンから拡大・縮小を選択したのち,画像のある個所を適当にクリックするとグリッドが表示されますので拡大を行ってください.
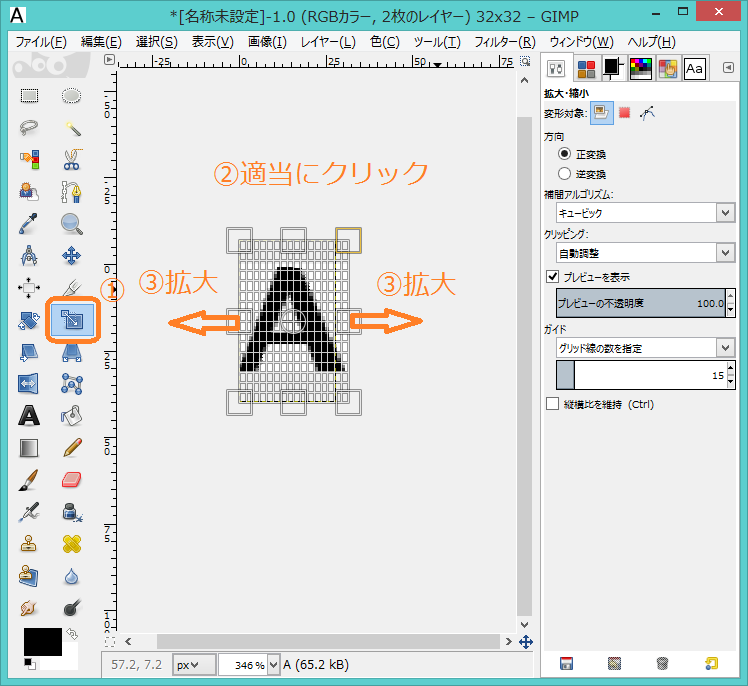
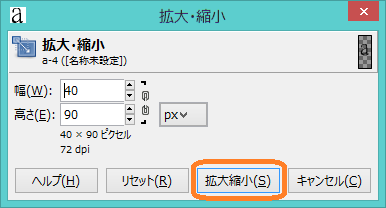
おおむね32×32になりましたら,下図のように「拡大縮小」ボタンを押してください.
最後に保存します.ただし,gimpの場合にはxcf(gimpの保存形式)以外の画像形式については「保存」とは言わず,「エクスポート」といいますので下図のように「名前を付けてエクスポート」を選択してください.
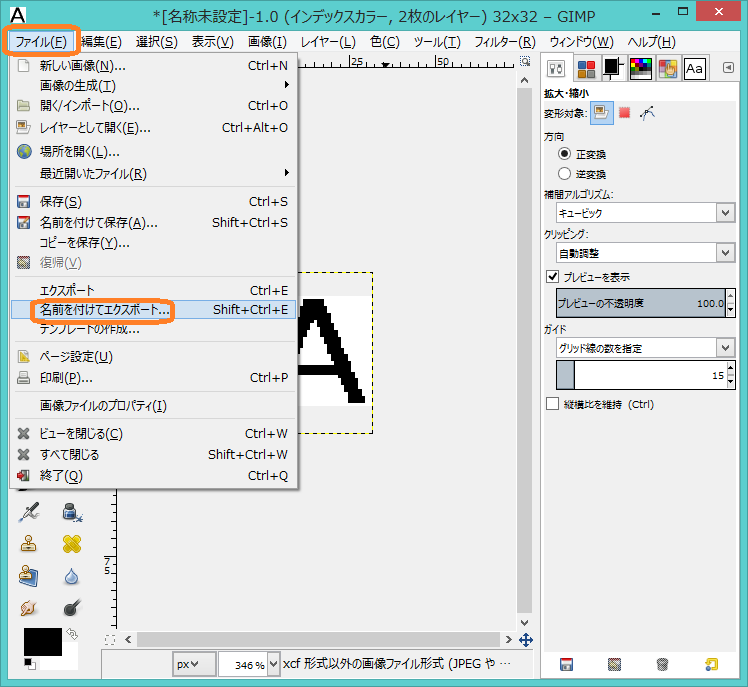
この例では,DigitRecognitionをCドライブの直下に置いているため,下図のようにC:\DigitRecognition\DictionaryDataの下に,「A」フォルダを作成します.
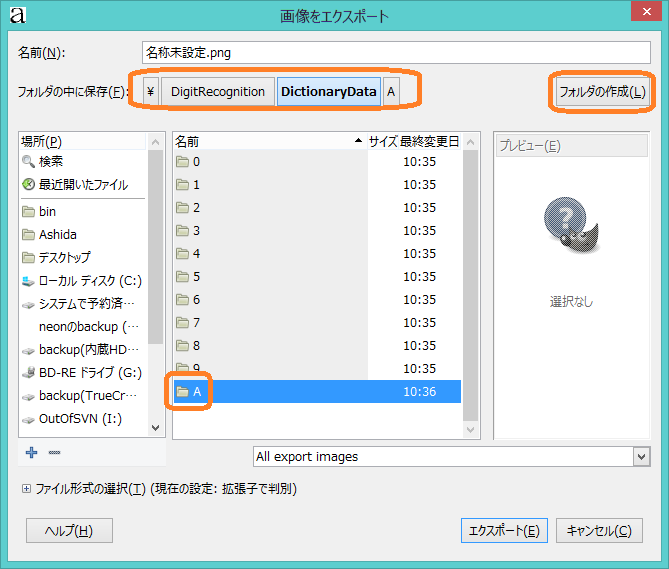
Aフォルダの中に,A-00pbmというファイル名で保存してください.
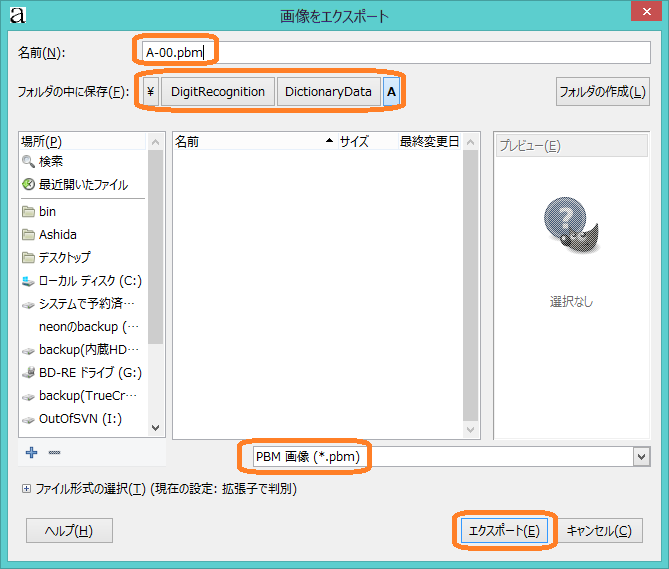
pbm形式にはRawとASCIIがあります.今回はASCII形式で保存してください.
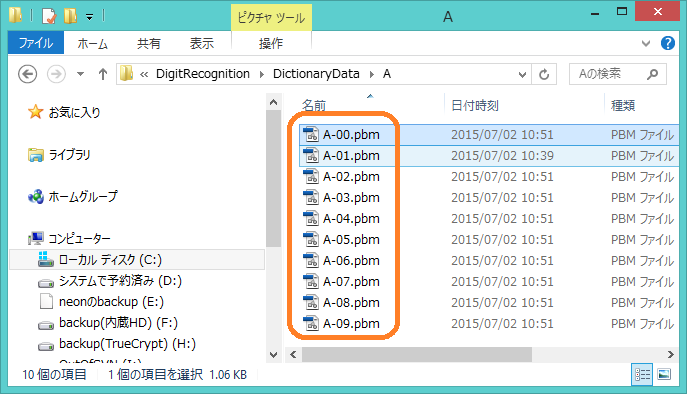
以上でAのためのパターンの1個が出来上がりました.より多くのフォントに対応するため,上記のような方法であと9個,全部で10個のパターンが必要です.もし,とりあえず動かしたいのであれば,A-00.pbmをA-01.pbm,A-02.pbm,...,A-09.pbmというようにコピーしてください.いずれの方法でも下図のようにAフォルダに10個のファイルを作成しましょう.
2:プログラムの変更
はじめに辞書を修正するため,辞書作成プログラムを修正します.C:\DigitRecognition\Program\MakeDictionaryフォルダにあるMain.cファイルを開いてください.下のように12行目にあるCHAR_NUMを10から11に変更しましょう.
/* * Main.c * * Created on: 2009/07/07 * Author: ashida */ #include <stdio.h> #include <stdlib.h> /* 認識する文字の数 */ #define CHAR_NUM 11 // !!!10から11に修正 /* 辞書として登録する文字の数 */ #define SAMPLE_NUM 10 /* 辞書のあるディレクトリ */ #define DICT_DIR "..\\DictionaryData\\" /* メッシュ特徴量の辞書名 */ #define MESH_DICTIONARY "Mesh.dict"
次に辞書画像を読み込むための関数_readBitmapsを修正します.下のプログラムリストは_readBitmapsの修正例です.制御変数iは0~10までの値を取ることになりますが,そのうち0~9まではこれまで同様の処理,10についてはアルファベットである「A」に対応するための処理を行うようにしてあります.なお,この修正により,大文字のアルファベットA~Zまでは対応します.
/* 画像を読み込む */
static void _readBitmaps(Bitmap bitmaps[][SAMPLE_NUM], unsigned int code[]){
/* 制御変数 */
int i,j;
/* ファイル名 */
char filename[FILENAME_SIZE];
/* 認識する文字の数だけ繰り返す */
for(i=0; i<CHAR_NUM; i++){
/* 辞書として登録する文字の数だけ繰り返す */
for(j=0; j<SAMPLE_NUM; j++){
/*!!!!! 変更開始 !!!!!*/
/* ビットマップファイル名を作成する */
if(i < 10){
sprintf(filename, "%s%d\\%d-%02d.pbm", DICT_DIR, i, i, j);
}
else{
sprintf(filename, "%s%c\\%c-%02d.pbm", DICT_DIR, (i-10)+'A', (i-10)+'A', j);
}
/*!!!!! 変更終了 !!!!!*/
/* ファイルより画像を読み込む */
readBitmap(&(bitmaps[i][j]), filename);
}
/*!!!!! 変更開始 !!!!!*/
/* 文字コードを記憶する */
if(i < 10){
code[i] = i+'0';
}
else{
code[i] = i-10+'A';
}
/*!!!!! 変更終了 !!!!!*/
}
}
以上でプログラムの修正は終わりです.C:\DigitRecognition\Programでmakeをし,MakeDictionary.exeを実行すると辞書が更新されます.その後,DigitRecognition.exeを実行してください.なお,比較対象はC:\DigitRecognition\RecognizedDataフォルダにある4-00.pbmとなっています.比較対象を変更するには,4-00.pbmを上書きするか,C:\DigitRecognition\Program\DigitRecognitionフォルダ内のMain.cの18行目にあるRECOGNIZED_CHARを変更してください.